SENTIENCE
The foundational vision-language-action model powering autonomous reason.
The foundational vision-language-action model powering autonomous reason.

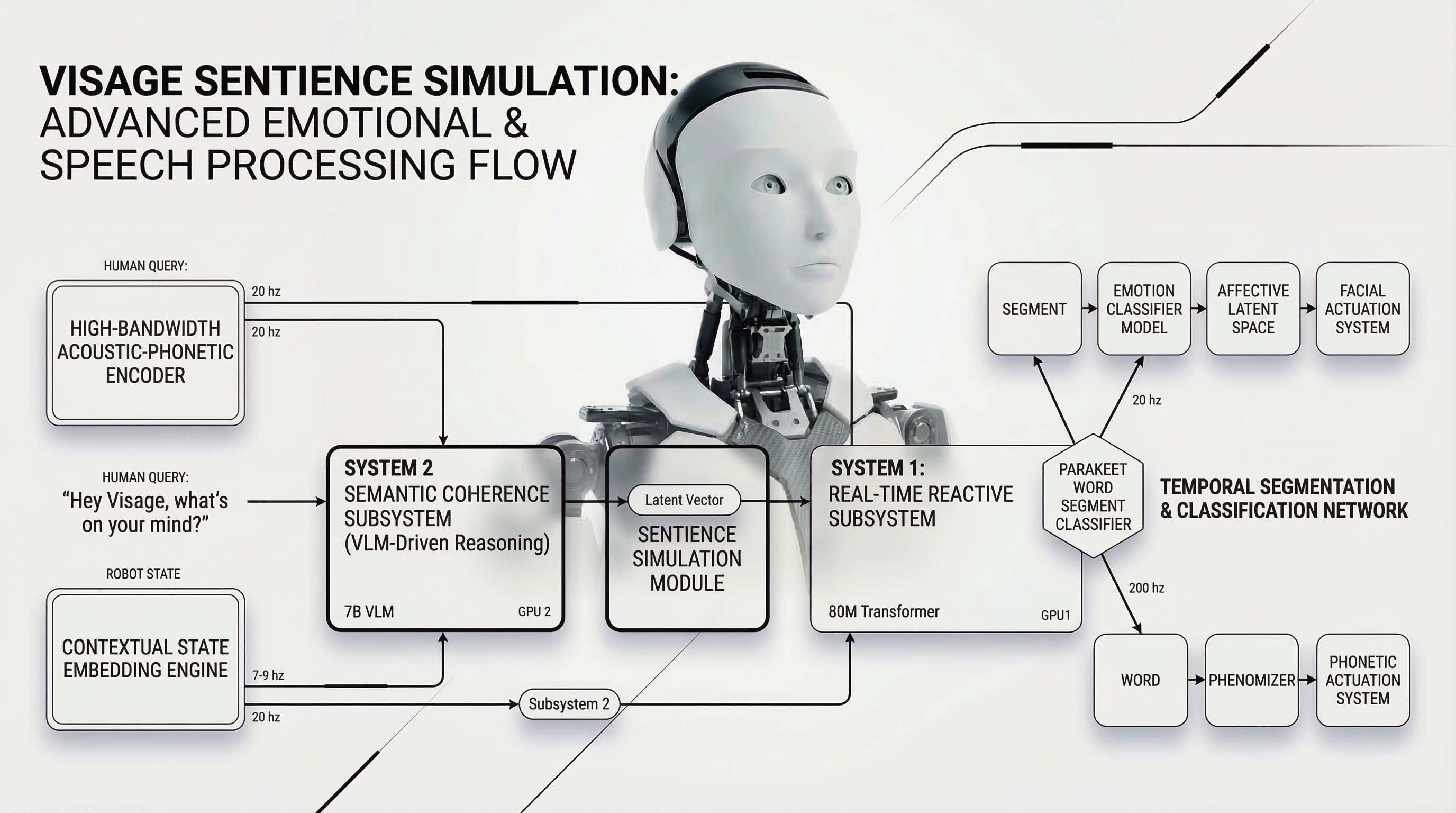
SENTIENCE is not just a reactive control system. It is a unified neural architecture designed to process multi-modal inputs—ranging from high-framerate stereo video to tactile force feedback—and synthesize them into a coherent understanding of the physical world.
By simulating physical outcomes before executing motor commands, SENTIENCE enables our hardware to "think" before it acts. This predictive reasoning layer is what allows VISAGE to operate safely around humans without pre-mapped environments.
The model is trained entirely end-to-end, meaning semantic understanding is directly tied to low-level motor primitives. When SENTIENCE sees a cup, it doesn't just recognize a bounding box; it understands the affordances required to grasp, lift, and pour.

While SENTIENCE can run in the cloud for large-scale training and simulation, its inference engine is optimized to run entirely on the edge, inside VISAGE's onboard compute.
Operating at disruptions instantly.
Fleet-wide data collection allows SENTIENCE to learn from edge cases, pushing updates to all deployed units overnight.
SENTIENCE is currently available exclusively via VISAGE hardware deployments. Partner API access is coming Q4 2026.
Inquire About Access